24 min to read
How to get more data...for free

In your work as a Data Scientist, there maybe times when you are not provided with sufficient data to build model or to analyze. In such times, you are required to get more data from external sources, or to be more specific, from the Internet! That is called ‘crawling’.
Today in this post, I will show you what is required and how to crawl data from the web (with R). This post also comes with code from my previous project. Link to the code in Github is published here.
Please note that the tutorial is specifically made for Dynamic Scrolling page only. This is an example of a dynamic scrolling page, where new element is loaded on the fly as you scroll to the end of the page.
1. Is web-crawling illegal?
Before doing any web-crawling/web-scraping, you need to carefully visit the website’s terms of services and copyright. This is because:
- Scraping often violates the terms of service of the target website. The terms of service of established data-heavy sites almost invariably prohibit data scraping. Violating the terms of service doesn’t mean that you’ve done something illegal (i.e., this is not a crime - you can’t go to prison for it). But it does mean that the website might be able to sue you for breach of contract.
- Publishing scraped content may be a breach of copyright. Depending on what the scraped content is and what you do with it, it may be a violation of the copyright holder’s rights. Facts themselves are not subject to copyright in the US, but creative expression is. You may be able to rely on the “fair use” defense if you use only portions of someone else’s creative expression in a way that adds value and is not mere regurgitation.
TL;DR: Web-crawling may not be illegal and there is a small chance you will get into prison for that. However legal it might be, web-crawling poses a high chance of being unethical.
When do you know your scraping is unethical?
It depends. I can think of many perfectly ethical cases of data gathering (and in fact have defended some forms of scraping, especially of facts, in a blog post - http://blog.everylodge.com/2012/02/how-everylodge-works-thoughts-on-copyright-terms-of-service/). But a lot of scraping is unethical. It is unethical to appropriate someone else’s creative work for profit. There are also a lot of bots out there scraping and “spinning” content, producing trash that clogs search engine results and adds no value to the internet.
2. What is required
2.1. HTML knowledge (or not)
Web-crawling is basically getting HTML element/text out of a website. To get yourself familiar with HTML, in a website, try pressing F12 and you will see a tab of Elements, that where the HTML code of the website is. Below is an example of the text in HTML, as you can see, all the contents of the website is stored there.
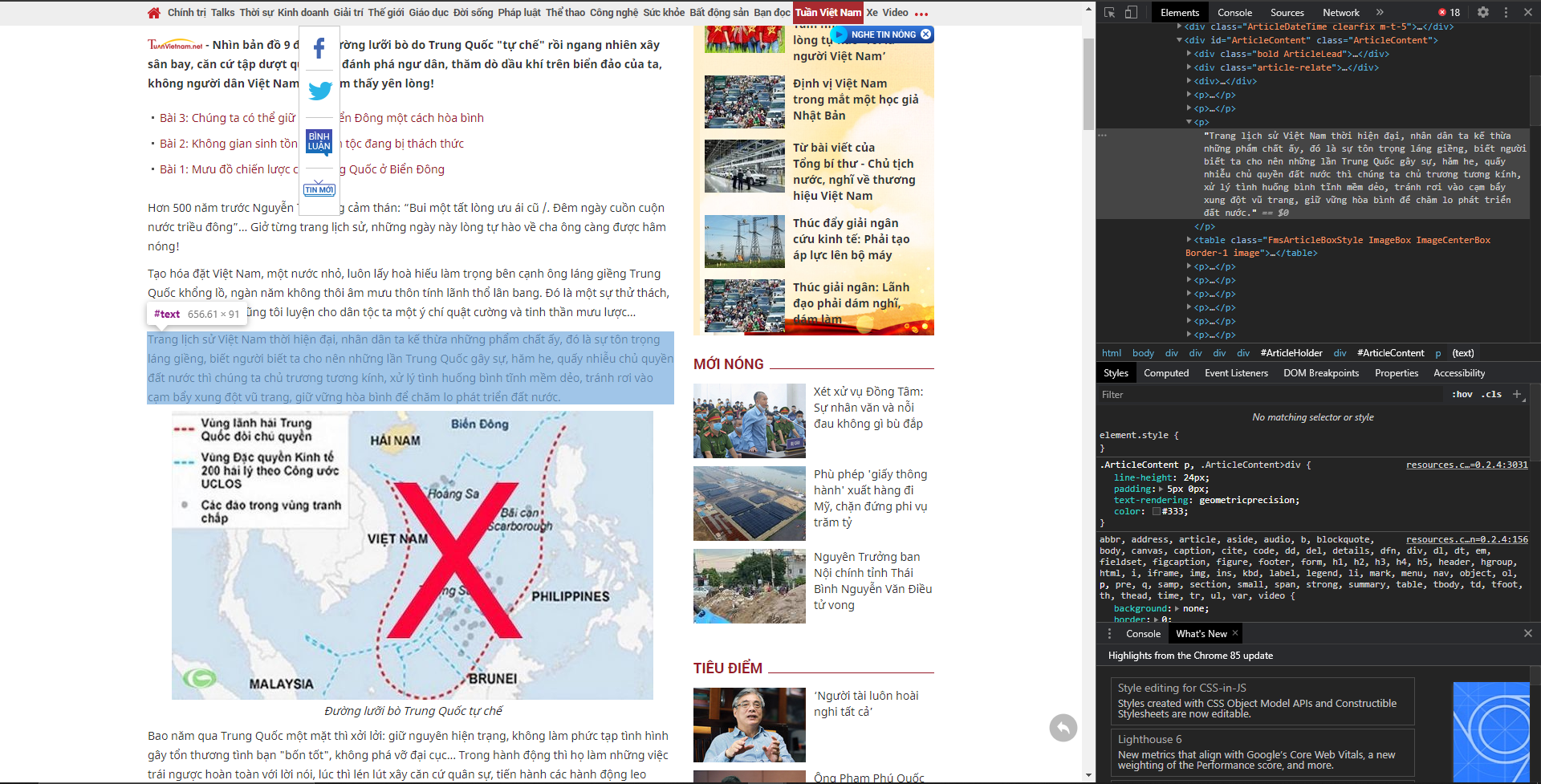
In order to learn HTML, you can refer to this great website: https://www.learn-html.org/. The website provides interactive tutorial, as well as step by step explanation.
For some of you who does not have enough time to learn HTML but still want to do some web-crawling, refer to this great extension, which can easily choose and extract element from any website: https://chrome.google.com/webstore/detail/selectorgadget/mhjhnkcfbdhnjickkkdbjoemdmbfginb
2.2. R Packages
As this tutorial is done in R, not Python, remember to download R and RStudio, find the tutorial here if you haven’t download these.
The packages to be used to crawl data from dynamic scrolling page is RSelenium and rvest. Other packages like tidyverse, stringr, leaflet, ggmap, etc. is for supplement use only.
# create a vector of packages that you will be using
packages <- c('tidyverse', 'rvest', 'RSelenium', 'stringr', 'leaflet', 'ggmap', 'magrittr', 'sp')
# create a vector of installed packages
installed_packages <- as.vector(installed.packages()[,c(1)])
# install missing packages
missing_packages <- setdiff(packages, installed_packages)
if (length(missing_packages) > 0) {
install.packages(setdiff(packages, installed_packages))
}
2.3. Webdriver
When you open the official page of the Selenium, the first thing you read is “Selenium automates browser” in “What is Selenium?” section. But in order to use Selenium, you have to use Selenium WebDriver. WebDriver comes in many versions for Chrome and Firefox. You can install the WebDriver for your favorite browser by accessing:
- Chrome: https://chromedriver.chromium.org/downloads
- Firefox: https://github.com/mozilla/geckodriver/releases
Personally I prefer Firefox, since it’s generally faster than Chrome.
2.4. Java
You also need to install Java in order to use Selenium (and many other packages in the future). Please find the link here: https://www.java.com/en/download/
3. Start your crawling
Okay so now let’s start your project in web-crawling. Consider the project as a car, first you need to fuel it up, run it, and then shut it down in the last phase.
3.1 Fuel up
3.1.1. Get a glimpse of your website-to-be-crawled
Here I am taking the Foody website as an example. My goal is to extract all the information of all the Café/Dessert in Hanoi. You can take a look at the page here.
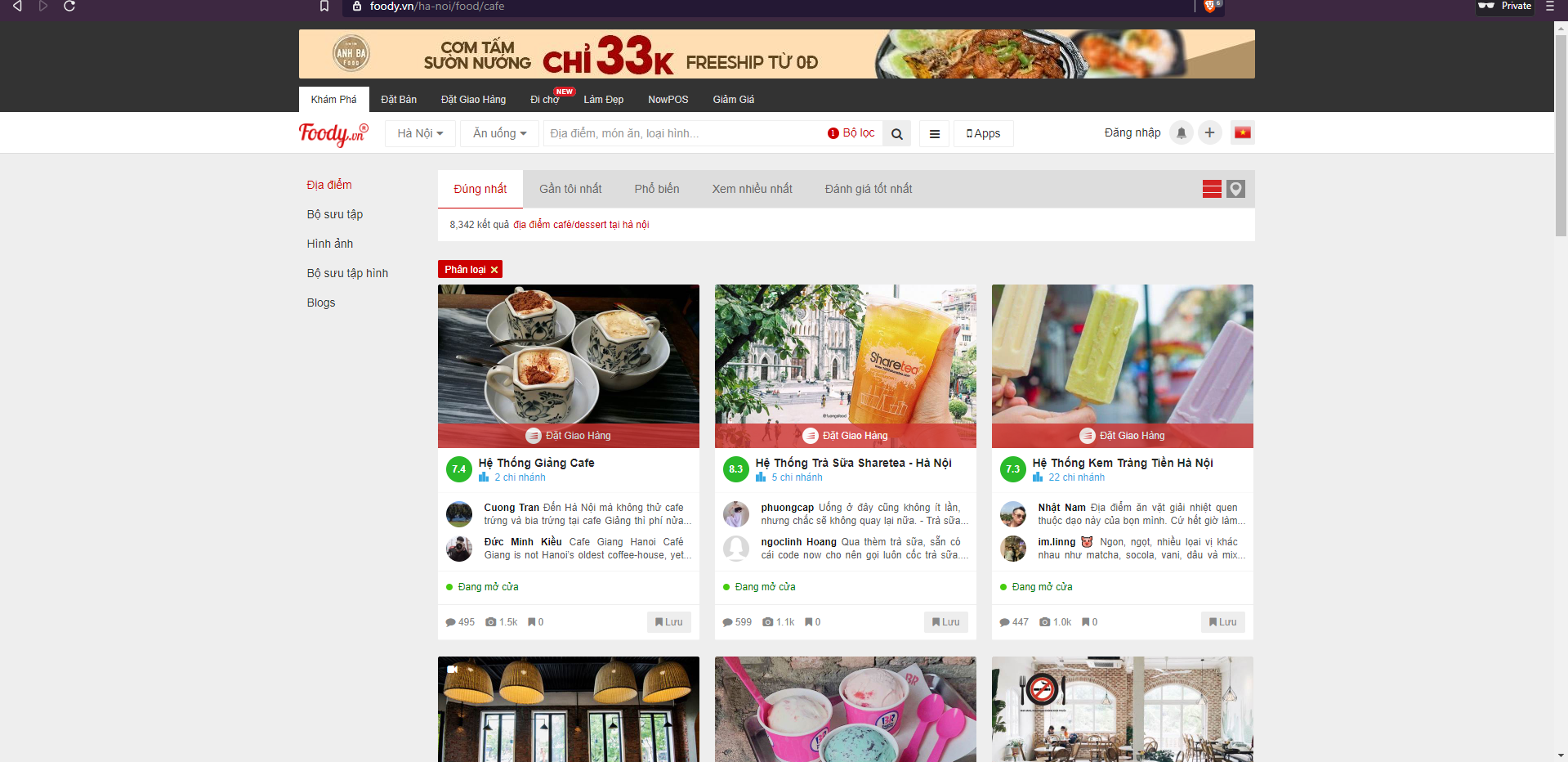
Problem with this page:
-
It is indeed a dynamic scrolling website, as you scroll down, more elements will be loaded. However, as you scroll down to page number 70 or 71, the website gets super laggy and you cannot load anything else, even if you force it to load more elements. This maybe because from such page, there are too many elements that are cramped into the page, making it too heavy for the back-end to handle.
Solution: Find another specific URL to narrow down the elements to be loaded in each page.
Detailed Solution: Find the request URL of the page by referring to the network tab when inspecting. Find the xhr type and press that element, that will get you to the request URL of the page. Take a look at that URL and you can see the part
page = ..., and that’s what get you to any specific page.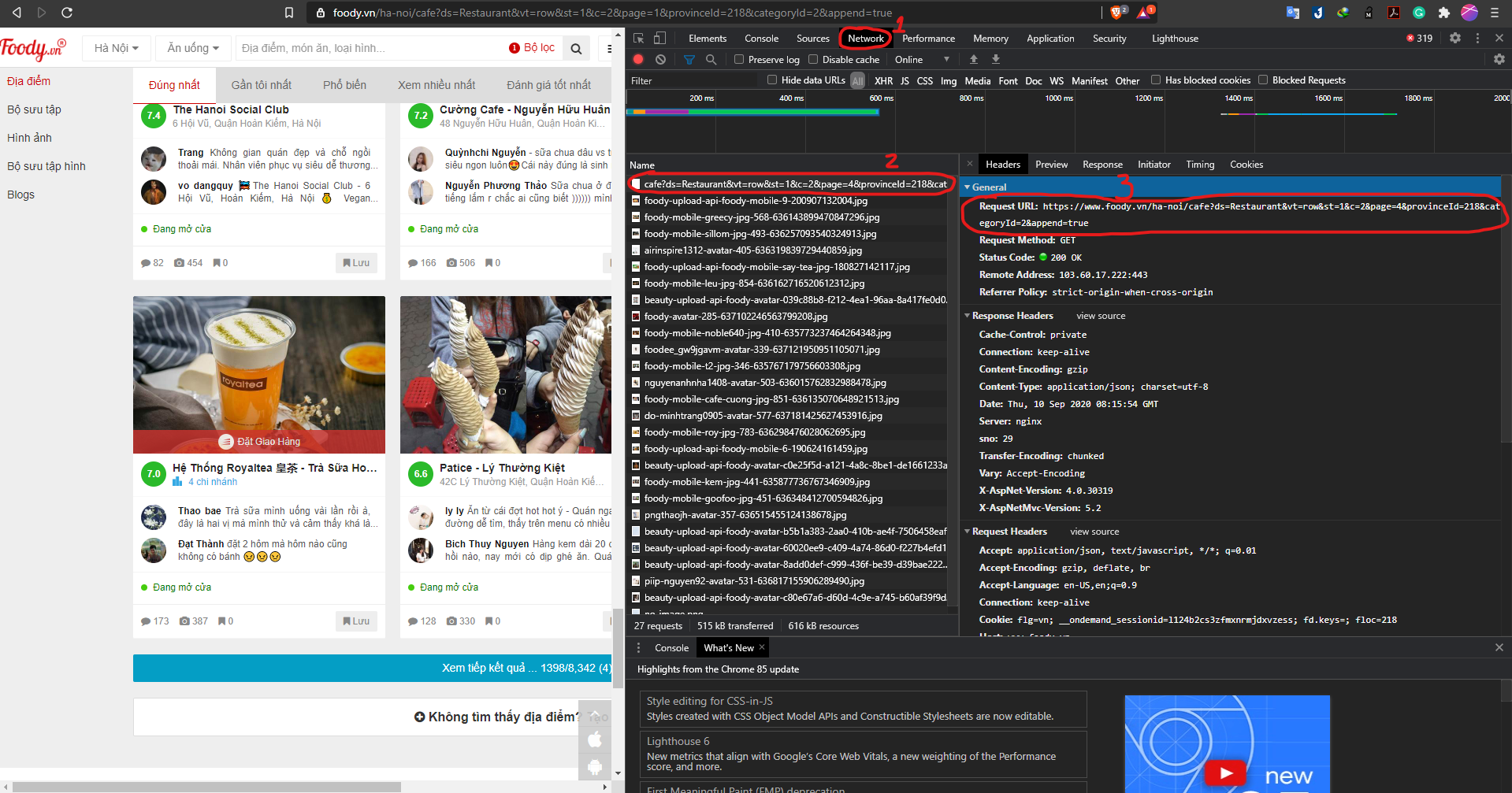
-
Another problem is that where the page direct you to depends on what type of restaurant you are clicking.
- If you click on the restaurants that have multiple branches, it will direct you to another intermediate page before getting to each specific restaurant.
-
If you click on the restaurants that have only 1 branch, it will direct you to that specific restaurant immediately.
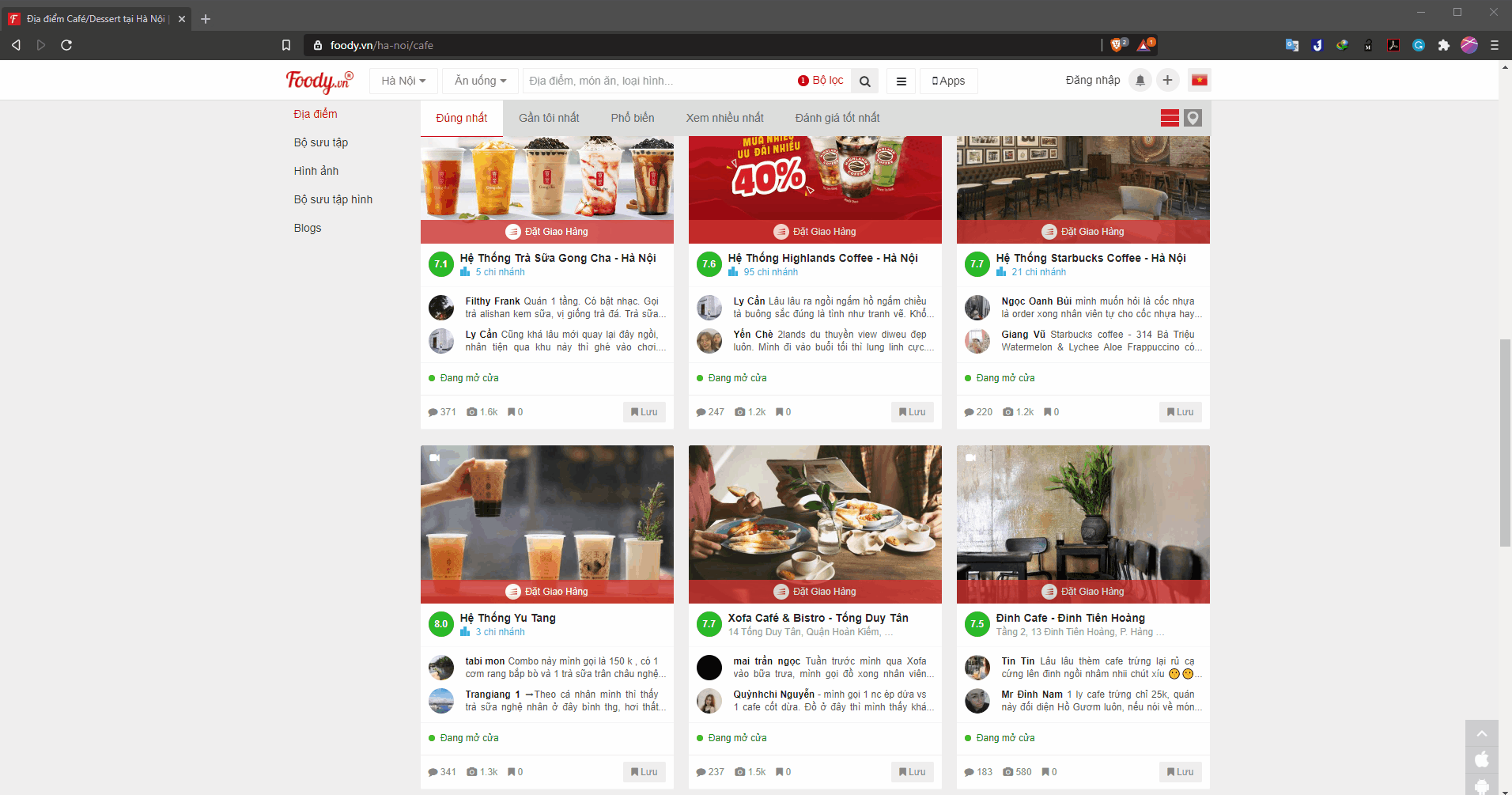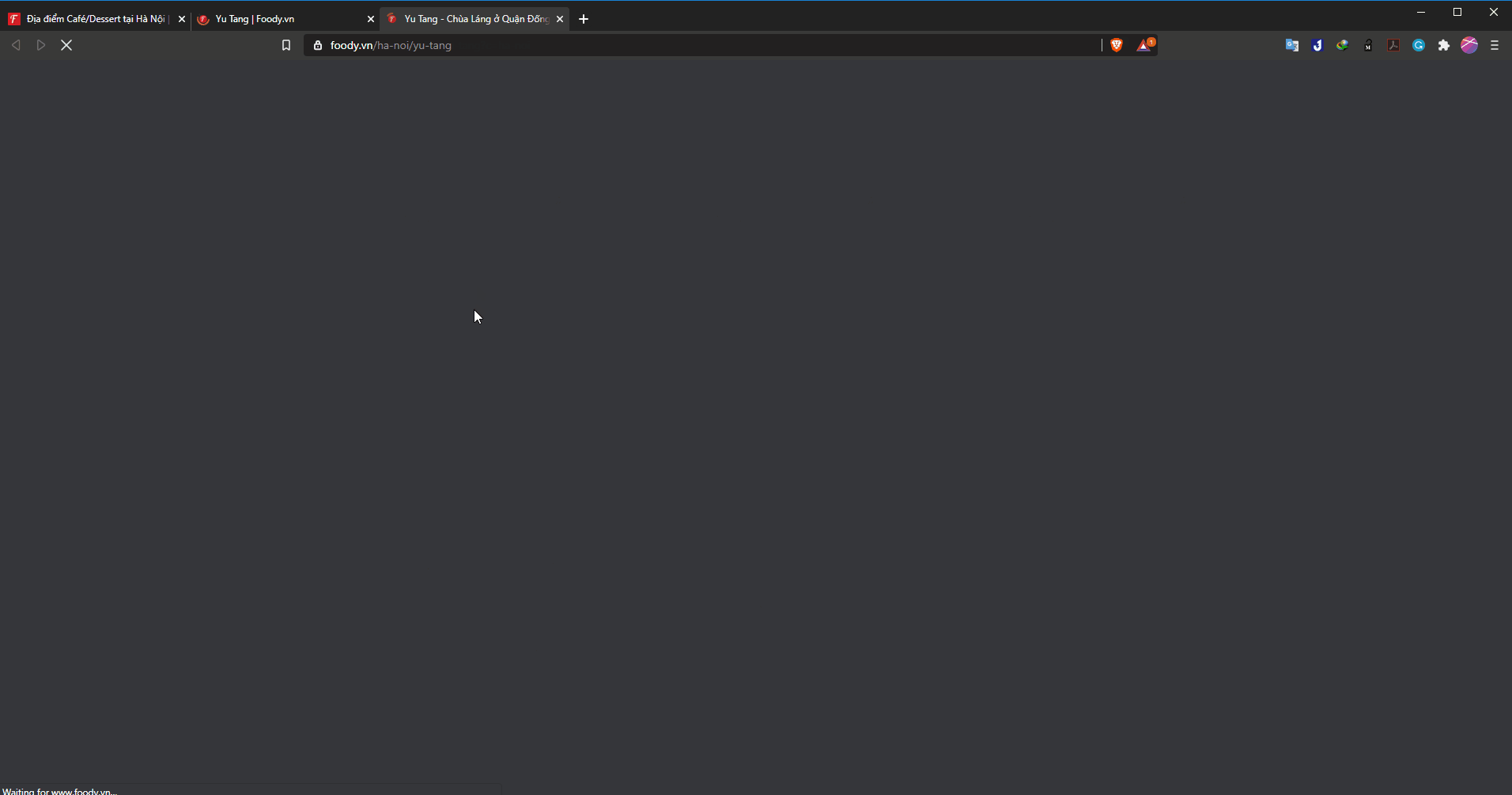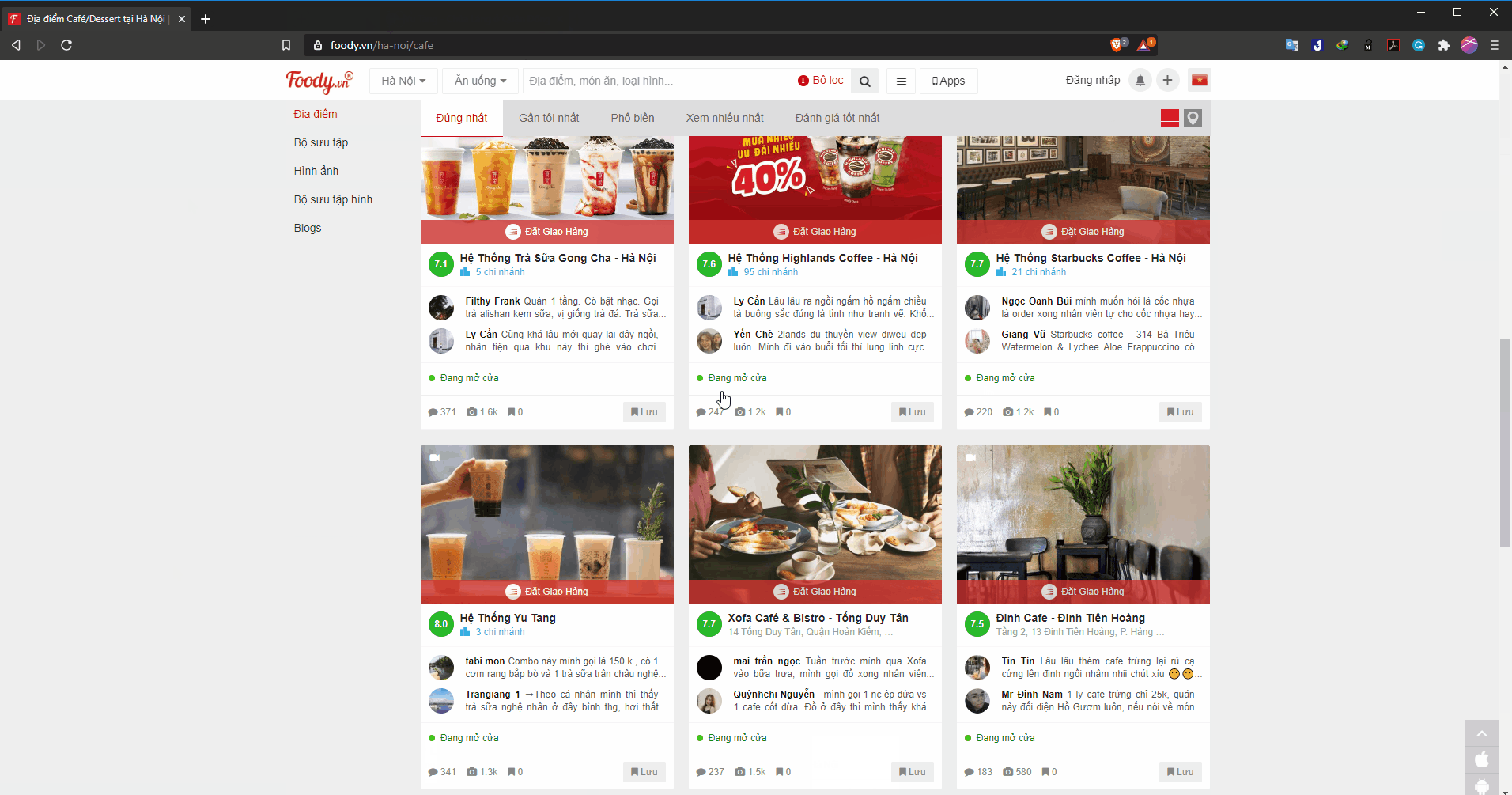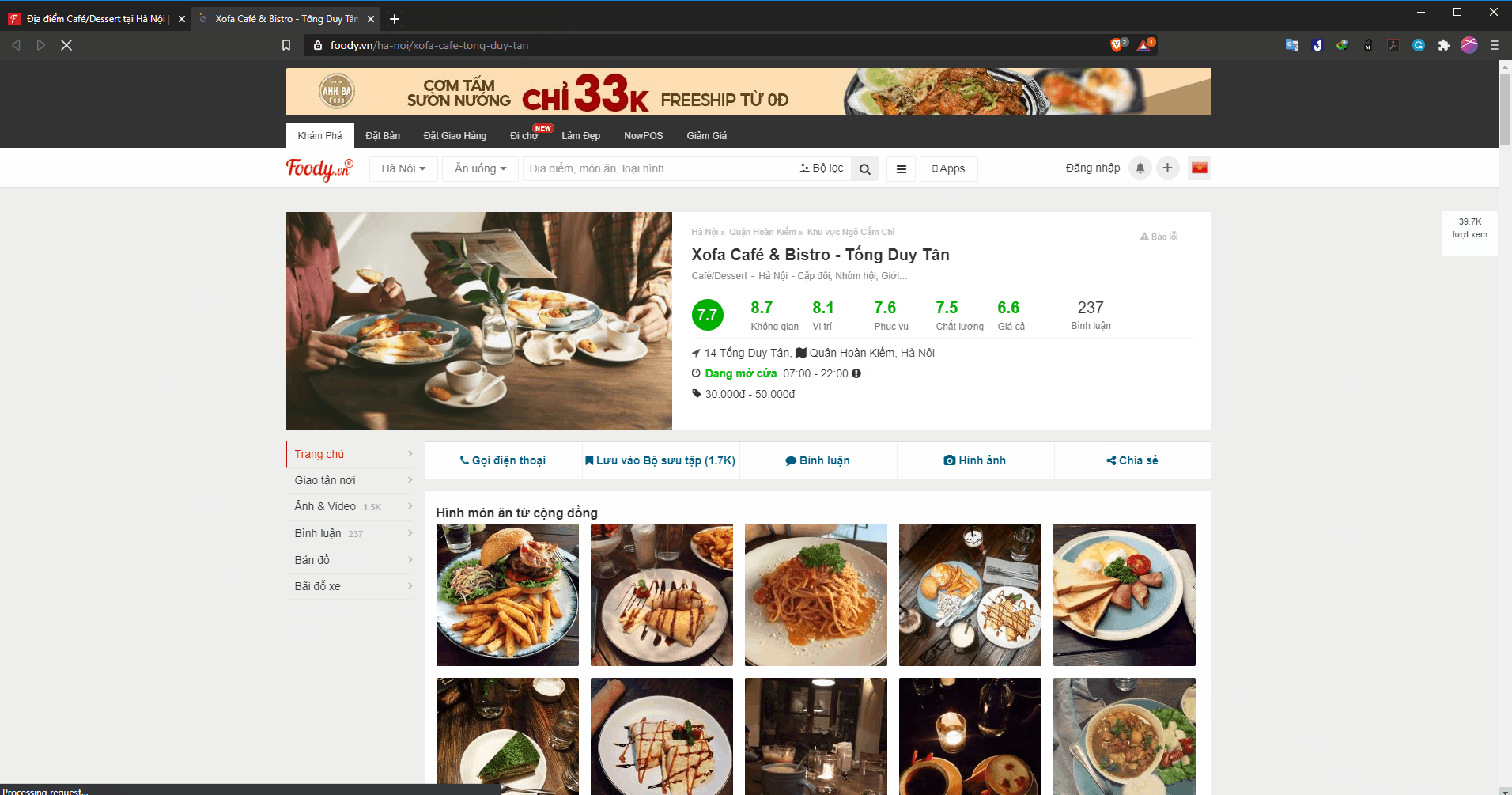
-
The last problem is that each time you press on a restaurant, it will open a new tab. This is not a problem but you need to choose what is convenient for you. If you want to use back/forward feature in the browser, you need to inject a new element to overwrite the existing one (or in other words, force the browser to open the link in the same tab). Otherwise, you need to change your handler (to control the tab) each time a new tab is opened. I use the latter solution, since we need to know a little bit of Javascript to inject elements.
3.1.2. Prepare your code
In R and any programming language, you need to load packages before using them. To do this in R, use the code:
# load packages
invisible(lapply(packages, library, character.only = TRUE))
Next, you need to initiate a session in Selenium and create any variables and function that will be used.
## function
### this function is used to switch window handler
myswitch <- function (remDr, windowId) {
qpath <- sprintf('%s/session/%s/window', remDr$serverURL,
remDr$sessionInfo[['id']])
remDr$queryRD(qpath, 'POST', qdata = list(handle = windowId))
}
### this function is used to get the text of a xpath in a page
get_html_text <- function(page_source, xpath, index=1) {
# get text by xpath
text <- (page_source %>%
html_nodes(xpath = xpath) %>%
html_text())[index]
# if no text is extracted, return empty string, otherwise return that text
if (identical(text, character(0))) {
return('')
} else {
return(text)
}
}
### this function is used to get the information of the restaurant
get_general_info <- function(page_source) {
info <- tibble(
title = get_html_text(page_source, "//div[@class = 'main-info-title']//h1"),
category = get_html_text(page_source, "//div[@class = 'category-items']//a[@title]"),
cuisine_type = get_html_text(page_source, "//div[@class = 'cuisines-list']//a/text()"),
customer_type = get_html_text(page_source, "//div[@class = 'audiences']/text()"),
avg_score = get_html_text(page_source, "//div[@class = 'microsite-point-avg ']"),
location = get_html_text(page_source, "//div[@class = 'microsite-top-points']//span", 1),
price = get_html_text(page_source, "//div[@class = 'microsite-top-points']//span", 2),
quality = get_html_text(page_source, "//div[@class = 'microsite-top-points']//span", 3),
space = get_html_text(page_source, "//div[@class = 'microsite-top-points']//span", 4),
service = get_html_text(page_source, "//div[@class = 'microsite-top-points']//span", 5),
comment_count = get_html_text(page_source, "//div[@class = 'microsite-review-count']"),
address = get_html_text(page_source, "//div[@class = 'res-common-add']//span//a//span[@itemprop = 'streetAddress']"),
district = get_html_text(page_source, "//span[@itemprop = 'addressLocality']"),
price_range = get_html_text(page_source, "//span[@itemprop = 'priceRange']/span"),
time = get_html_text(page_source, "//div[@class = 'micro-timesopen']//span[3]"),
area = get_html_text(page_source, "//a[@itemprop = 'item']//span[@itemprop = 'name']")
)
return(info)
}
## variable
page_source <- list() # store the source_code of a page
multiple_branches <- list() # store the indices of multiple branches restaurants
single_branches <- list() # store the indices of single branches restaurants
shop_name <- list() # store the name of the restaurants
click_field <- list() # field to click in the 'mother' page
currWindow <- list() # window handler of the 'mother' page
general_info <- list() # store the information of multiple branches restaurants
windows <- list() # get all windows handle after clicking into a multiple branches restaurant
otherWindow <- list() # get windows handle after clicking into a multiple branches restaurant of pages except 'mother' and 'intermediate' page
intermediate_handle <- list() # handle of the intermediate page
windows1 <- list() # get all windows handle after clicking into a branch
otherWindow1 <- list() # get windows handle after clicking into a branch of pages except 'mother' and 'intermediate' page
windows2 <- list() # get all windows handle after clicking into a single branches restaurant
otherWindow2 <- list() # get windows handle after clicking into a multiple branches restaurant of pages except 'mother' page
general_info_2 <- list() # store the information of single branches restaurants
a <- 1 # just a counter
e <- 1 # just a counter
click_field_branches <- list() # field to clicks in intermediate page
The most confusing part maybe the get_general_info() function. You maybe wondering where all those in the quote come from. They are called xpath, and you can collect it using the CSS selector I introduced above.
3.2. Get your car running
for (page_num in 1:84) {
## navigate to each pages
remDr$navigate(paste0("https://www.foody.vn/ha-noi/cafe?ds=Restaurant&vt=row&st=1&c=2&page=", page_num, "&provinceId=218&categoryId=2&append=true"))
## get page's source_code (including all html code)
page_source[[page_num]] <- remDr$getPageSource()
## get name of the restaurants
read_html(page_source[[page_num]][[1]]) %>%
html_nodes(css = "h2") %>%
html_text() %>%
str_remove('^([[:space:]]+)') %>% # trim spaces at the beginning
str_remove('([[:space:]]+)$') %>% # trim spaces at the end
str_replace_all('[\n\r]','') -> shop_name[[page_num]]
## get index of multiple branches restaurants
which(str_detect(shop_name[[page_num]], 'Hệ thống')) -> multiple_branches[[page_num]]
## get index of single branches restaurants
which(str_detect(shop_name[[page_num]], 'Hệ thống', negate = TRUE)) -> single_branches[[page_num]]
## pick the element to click to get to the page of that specific restaurant
remDr$findElements(using = "xpath", "//h2/a") -> click_field[[page_num]]
## get handle of the 'mother' page (which include many restaurants), use to get back to the mother page later
currWindow[[page_num]] <- remDr$getCurrentWindowHandle()[[1]]
## ---------------- for restaurant with multiple branches ------------------
for(i in multiple_branches[[page_num]]) {
## click link
click_field[[page_num]][[i]]$clickElement()
## get handle
windows[[i]] <- remDr$getWindowHandles() # get all windows handle
otherWindow[[i]] <- windows[[i]][!windows[[i]] %in% currWindow[[page_num]]][[1]] # other handle apart from current 'mother' one
## switch to other window
myswitch(remDr, otherWindow[[i]][[1]])
## ------ click to a branch then get information about that branch -----
## get into a branch
remDr$findElements(using = "xpath", "//h2/a") -> click_field_branches[[i]]
## get the handle of the intermediate page (to get back later)
intermediate_handle[[i]] <- remDr$getCurrentWindowHandle()[[1]]
## loop to get information about each branch
for(j in 1:length(click_field_branches[[i]])) {
## click link
click_field_branches[[i]][[j]]$clickElement()
## get handle
windows1[[j]] <- remDr$getWindowHandles() # get all windows handle
otherWindow1[[j]] <- windows1[[j]][!windows1[[j]] %in% c(windows1[[j]][[1]], windows1[[j]][[2]])] # other handle apart from current 'mother' and 'intermediate' one
## switch to other window
myswitch(remDr, otherWindow1[[j]][[1]])
## extract info of that branch
page_source1 <- read_html((remDr$getPageSource())[[1]])
general_info[[a]] <- get_general_info(page_source1)
## close the tab for that branch and switch to the intermediate tab
remDr$closeWindow()
remDr$switchToWindow(intermediate_handle[[i]][[1]])
a <- a + 1
}
## close intermediate tab and switch to mother page
remDr$closeWindow()
remDr$switchToWindow(currWindow[[page_num]])
}
## ---------------- for restaurant with single branches ------------------
for(g in single_branches[[page_num]]) {
## click link
click_field[[page_num]][[g]]$clickElement()
## get handle
windows2[[g]] <- remDr$getWindowHandles() # get all windows handle
otherWindow2[[g]] <- windows2[[g]][!windows2[[g]] %in% currWindow[[page_num]]][[1]] # other handle apart from current 'mother' one
## switch to other window
myswitch(remDr, otherWindow2[[g]][[1]])
## extract info of that branch
page_source2 <- read_html((remDr$getPageSource())[[1]])
general_info_2[[e]] <- get_general_info(page_source2)
e <- e + 1
## close tab for that restaurant and switch to mother page
remDr$closeWindow()
remDr$switchToWindow(currWindow[[page_num]])
}
}
Now you have prepared your helper functions, it’s time to start your crawling process. However, as stated in the above part, the flows for multiple branches and single branch restaurants are different. As a result, we need to determine which are multiple branches and which are single branches, then use a different for loop for each type of restaurants.
The general idea is that you would want to get into the page for every specific restaurants, extract the information, and get out. Then repeat that process again and again and again.
The detailed steps are as follow:
- Step 1: Access each page of the website (‘mother’ page)
-
Step 2: Extract every relevant information in that page:
- Determine the names of the restaurants appear in the page
- Determine which are multiple branches restaurants, which are single branch restaurants
- Determine where to click to get into the details of these restaurants
-
Step 3: Click the link determined above to dive into a specific restaurant. This will result in different output based on what type of restaurants we are diving into.
- For multiple branches restaurant: the output is a listing of branches of that restaurant
- For single branch restaurant: the output is the final page including specific information for that restaurant
- Step 3.1 (for multiple branches restaurants only): Determine where to click to get into the specific branch of a restaurant and click into that link to get to the final page of that branch.
- Step 4: Extract all the information of that restaurant (branch of restaurant) from that page.
- Step 4.1 (for multiple branches restaurants only): Get back to the intermediate page and repeat step 3.1, 4, 4.1 until we have accessed all the branches
- Step 5: Get back to the ‘mother’ page and repeat the process for another restaurant.
Finally, we store the information of 2 different types of restaurants into 2 different dataframe called general_info and general_info_2.
3.3. Finalize
Note that our output is in the form of list. As a result, we need to convert it into dataframe for further analysis.
do.call(rbind.data.frame, general_info) -> final_multiple_branches
do.call(rbind.data.frame, general_info_2) -> final_single_branch
Most of the time, the output we get from HTML code is not clean. Thus, another step for data cleaning is required. What to clean varies on a case by case basis. For this specific example, just take the code below for your reference:
loca_process <- function(location_x) {
location_x %>%
mutate_all(function(x) str_replace_all(x, '^((\\s+)(\"*)|(\"*))(.+)((\\s+)(\"*)|(\\s+))$', '\\5')) %>%
mutate_all(function(x) str_replace_all(x, '^-\\s+', '')) %>%
mutate_all(function(x) str_replace_all(x, '\\s+$|^\\s+', '')) %>%
unite('address', address, district, sep = ', ') %>%
separate(price_range, c('lower_price', 'upper_price'), sep = ' - ') %>%
separate(time, c('time1', 'time2'), sep = ' \\| ') %>%
separate(time1, c('open_1', 'close_1'), sep = ' - ') %>%
separate(time2, c('open_2', 'close_2'), sep = ' _ ') %>%
mutate_at(vars('lower_price', 'upper_price'), function(x) str_replace_all(x, '\\.|Ä|click_field_branches', '')) %>%
mutate_at(vars('lower_price', 'upper_price'), function(x) str_sub(x, end = -2)) %>%
mutate_at(vars('avg_score', 'location', 'quality', 'space', 'service', 'comment_count', 'lower_price', 'upper_price'), as.double)
}
loca_process(final_single_branch) -> final_single_branch
loca_process(final_multiple_branches) -> final_multiple_branches
Now we have gone through the basic process of web-crawling. Hope that you can try it with your own project!

Comments